Scientific Data| Source | Data |
Scientific Data is a peer-reviewed open-access journal for descriptions of datasets and research that advances the sharing and reuse of research data. The primary content-type, the Data Descriptor, combines traditional narrative content with structured descriptions of data to provide a framework for data-sharing to accelerate the pace of scientific discovery. These principles are designed to align with and support the FAIR Principles for scientific data management and stewardship, which declare that research data should be Findable, Accessible, Interoperable and Reusable.
The SU-EATABLE LIFE database represents a significant step towards promoting sustainable diets and mitigating environmental impacts in the agricultural and food sectors. By offering a comprehensive compilation of carbon (CF) and water (WF) footprint values for various food commodities, it equips citizens and industry stakeholders with essential information to make informed choices. Utilizing a standardized methodology, the database extracts data from peer-reviewed articles and grey literature, ensuring reliability and accessibility. Notably, its innovative approach to uncertainty treatment and data quality assurance establishes a robust foundation for evaluating the environmental impact of dietary shifts and informing global environmental policies. The database's repeatability and potential for expansion make it a valuable resource for managers and researchers seeking science-based solutions in the food sector.
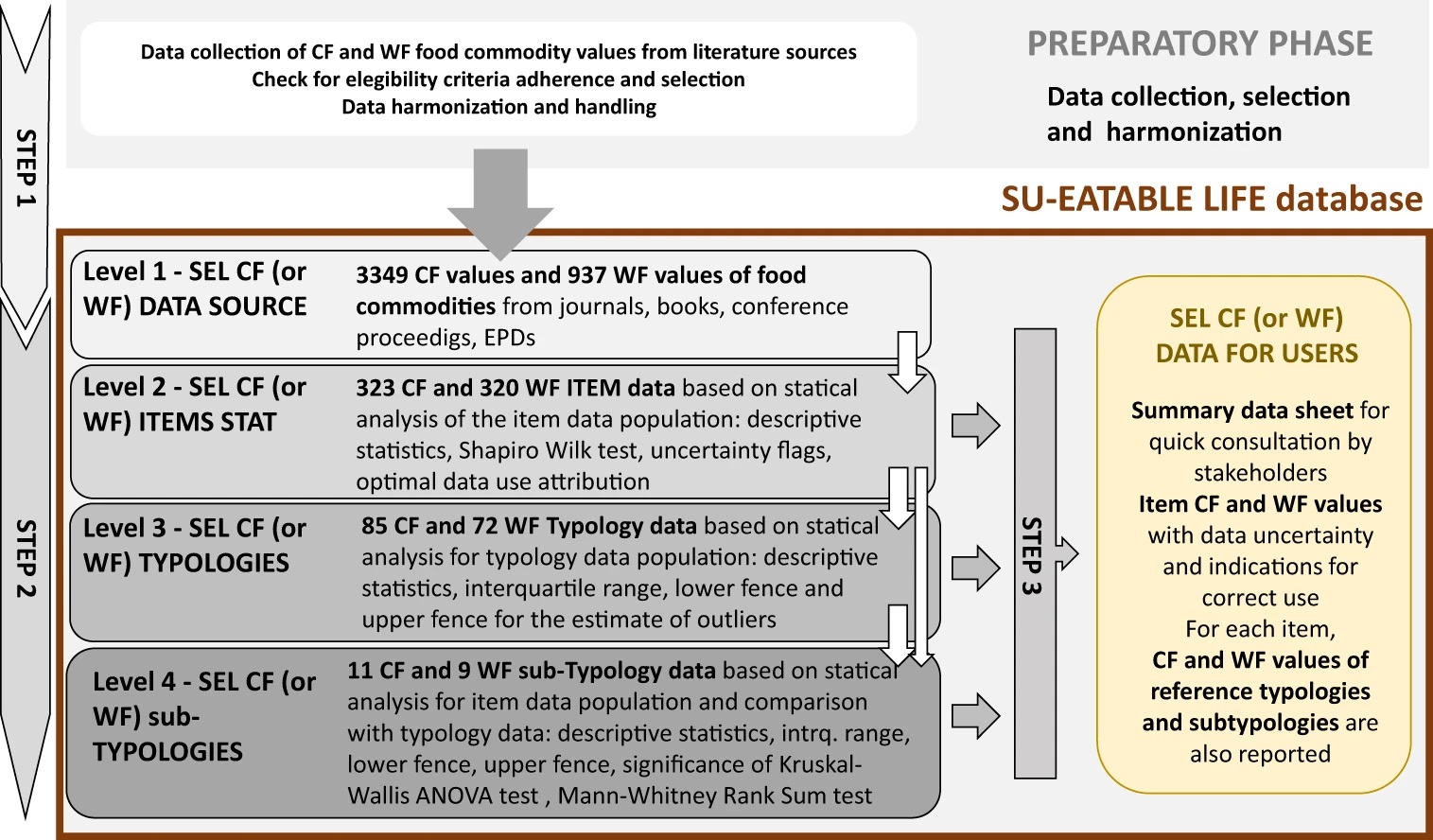
Figure | General outline of the different construction steps of SU-EATABLE LIFE (SEL) database. Step 1 includes the preparatory phase where studies were collected from literature and public repositories, selected on the basis of eligibility criteria, CF and WF values of food commodities extracted and harmonized, and then reported into the level 1 information of the SEL database. In Step 2 the other layers of information are created which represent different levels of aggregation of data reported in level 1. CF and WF values statistical analysis are reported for food items (level 2), typologies (level 3) and sub-typologies (level 4). In Step 3 the complex set of data reported in Level, 1, 2 and 3 are summarized into an easy to use dataset suitable for quick consultation by technical and not technical users.





